代谢组学是对生物体某一特定组分所包含的所有代谢物进行定性及定量分析,并研究该代谢组在外界干预或疾病生理条件下动态变化规律的一门学科。代谢组学是一门交叉性极强的学科,我们经常讲,代谢组学是用物理学原理的设备,检测化学原理的化合物,然后通过计算统计学,分析生物学机理,最终阐述医学等各种现象,真的是相当的复杂。
百趣生物亮哥从事代谢组学检测分析工作十几年,从不懂到懂一点,也是有非常漫长的过程。然而最近看一些文章,听一些报告,和客户朋友聊一些天,发现大家对代谢组学研究依然有很多误区。故而总结这十大误区供大家讨论及参考:
误区十:OPLS-DA模型能将两组分开即表示两组之间有差异?
很多人做代谢组学数据分析,当拿到OPLS-DA模型结果时,一看两组之间分的很开(见下图),瞬间就兴奋了,这结果杠杠的。
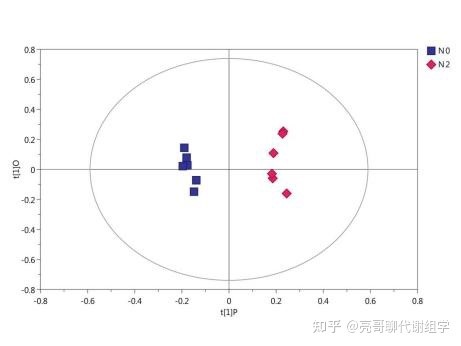
图1. 两组之间OPLS-DA模型得分图
然而对结果的错误理解,往往是投稿被拒噩梦的源头。
当我们拿到一个分的很开的OPLS-DA模型时,切莫匆忙得出“两组之间有明显差异”的结论。因为这个模型极有可能是一个过拟合的模型。
那么如何才能判断一个OPLS-DA模型的好坏以及如何判断OPLS-DA模型是否过拟合呢?
首先我们要了解一下OPLS-DA模型的一个基本原理。
OPLS-DA(正交矫正偏最小二乘法判别分析)模型是一个有监督的机器学习方法,最早是2002年由Trygg和Wold在PLS算法基础上建立了OPLS得来。
OPLS-DA作为一个有监督的模型,意味着模型使用了两组分类信息作为分类的Y变量,也就是说模型事先知道哪些样品是哪组的,然后开始建模,其第一主成分(也叫预测主成分)呈现的是两组之间的差异信息。其第二主成分呈现的是同组内的差异信息,故而我们看到的图大概率都是能分得很好的。
而模型的两个得分值,R2Y代表了模型的可解释性,也就是说模型中有百分之多少的信息能解释我们事先知道的分类变量Y,R2Y约接近1,说明能解释两组分类的信息越多,也就是我们说的两组之间的差异越大。同时模型自己做了一个自我交叉验证(Cross Validation),也就是我们平常说的七折交叉验证、十折交叉验证、留一法交叉验证等。通过交叉验证模型计算出一个Q2Y,以此来判断模型的可预测性。Q2Y越接近1,说明模型的可预测性越强,也就是我们说的模型越可靠。
如图1模型,其R2Y=0.909,Q2Y=0.672,说明模型的可解释很强,可预测性尚可。根据经验,Q2Y最好不要低于0.4。
为了进一步验证模型的可靠性,除了采用交叉验证这种内部验证的形式之外,我们还可以采用置换检验(permutation test)这种外部验证的方式。

图2. Permutation test(非图1的检验图)
置换检验的图到底该怎么看呢?
百趣生物亮哥来带大家看一下官方教程的解释:

总结一下就是两点:
1. 原始的R2Y和Q2Y(最右边的两个点)总是大于左边那些置换后对应的值(左边那些散点)。
2. 看截距,根据经验判断,优秀的模型R2Y的截距不超,0.3-0.4,Q2Y的截距不超过0.05(通常为负值)
在很多的实际的项目中,尤其是临床样品的检测项目,能满足两条斜线的斜率为正,且Q2Y的截距不超过0.05就很好了。所以可以看出图2的置换检验结果also good,但不是很理想,有一定的过拟合,要警惕结果的假阳性。
总结一下,OPLS-DA模型不能只看得分图能不能分开,而是要看R2Y和Q2Y的得分值以及外部检验的结果是否通过。可以说,写文章时如果只秀能分开的得分图,不展示得分值和检验结果,那是赤裸裸的耍流氓。
文章转载自知乎@亮哥聊代谢组学












































 关注公众号
关注公众号 安卓客户端
安卓客户端










发表评论
注册或登后即可发表评论
登录注册
全部评论(0)