2022-06-16

开始的话
一、原始混沌

神农氏

希波克拉底
这个阶段,无论东西方,都是通过主观的观察和盲目的试验来发现药物,这种观察性研究先天的局限性在于观察者无法排除无处不在的各种干扰因素。
二、端倪初现
中世纪的“医学王子”阿维森纳(Avicenna)做了一个可以流芳百世的试验。他将两只体质相同、喂养方式相同的小羊放在两个完全不同的环境里圈养,一只生活环境平静安逸,另一只却邻狼而居。不久后,后者逐渐消瘦而死去。
这个试验的伟大之处就在于两点,一是设立了对照,二是注意了组间的均衡。现在看来此试验非常粗糙,结果不可靠,但是它包含的通过对照来求证干预措施效果的伟大思想简直光芒万丈。
与此同时,我国宋代苏颂所著的《本草图经》记载了一个类似的“对照试验”,教如何分辨上党人参的功效。试验选择了两个人,一人口含人参,另一人不含人参,分别步行三里地。结果发现,不含人参者大喘,口含人参者则呼吸自如。这也被认为是中国最早的含有朴素对照思想的临床试验。

人参的对照试验
遗憾的是,这种对照思维并没有引起关注,在之后的数百年间,再也没有得到发展。于是,万古如长夜,在等待一盏明灯。
16世纪的坏血病是远洋海员深深恐惧的“夺命瘟神”。
英国皇家海军的一名外科医生——詹姆斯·林德博学多才,富有怀疑精神。质疑大量关于坏血病的民间疗法,于是亲自设计试验,探究真正有效的治疗方法。
选择12个严重病例,分成6组,每组2人,所有人每天正餐都相同,辅食则不同,这些辅食正是当时流传的治疗坏血病的方法。分别是:醋;稀释的硫酸;苹果酒;海水;肉豆蔻+大蒜+辣根;两个橘子+一个柠檬。最终结果是吃了橘子和柠檬的2名海员症状逐渐好转康复。
此后,其实是40多年后,英国海军部下令所有船只只供应柠檬汁,效果立竿见影,到18世纪末,坏血病便基本从英国海军中消失了。

柑橘和柠檬治疗坏血病的试验

金属棍电磁作用试验
安慰剂效应被发现后,西方医学发展进程出现重大转折,药物临床试验的方法学也自对照思维确立以来,取得历史性的突破。
五、医患和睦
医学领域对安慰剂效应的无线痴恋,以至于在19世纪相当一段时间内,西方医生不再关心如何治疗患者,而是让自己变成一个安慰者、观察者和记录者。安慰迅速取代了治疗,医学从积极进取转向了消极无为。吊诡的是,这一段时期竟然成为西方历史上医患关系的“黄金时期”。
安慰剂之所以能发挥效应,前提是患者视“假药”为“真药”,也就是说,患者处于被蒙蔽的状态。
那么,是不是到此为止,就解决了关于临床评价客观公正无偏倚的一切问题呢?NO!
临床试验是以人为研究对象,个体之间不管是先天还是后天都千差万别,如果研究者在分组时,有意或者无意把病情轻的年轻的个体都分在治疗组,而病情重或者年龄大的个体都分组对照组,那么即使试验结果表明治疗组的疗效远远好于对照组,仍然无法确定是因为研究药物导致还是两组之间个体差异导致,反之亦然。
这种组间的不均衡带来的便宜如何解决呢?自然是想尽一切办法让两组情况均衡化了。那么如何实现组间均衡化呢?
第一个思路是匹配。就是在分组前按照个体的基本特征进行组间匹配,从而实现两组间的均衡化。但是这种做法的有个问题,个体差异因素又很多,比如病情严重程度,年龄,性别,身体强弱等等,而在分组前往往不知道哪些特征对结果有决定性影响。而且当特征因素很多时,又很难做到对全部特征实现分组均衡。
第二个思路就是随机化。就是通过不参杂任何倾向性的随机化方法,让每个个体被随机的分配到任何一组,达到组间的均衡。正是随机化思想在临床试验中的应用,推动了临床试验方法学走向成熟。
英国著名统计学家罗纳德·艾尔默·费希尔(Ronald Aylmer Fisher)在1925年首次提出试验设计的随机化原则。1935年在《试验设计法》中对随机化做了系统阐述,并指出随机化是统计分析的前提条件。他在此书里更是提出了著名的“试验设计三原则”——随机化、区组控制和重复。1937年,费希尔在《医学统计学原则》中提出了严格遵守随机化是临床试验的必要条件,奠定了临床试验方法学的理论基础。

链霉素治疗结核病的试验
是否引入了随机化就解决了临床试验评价方法学的所有问题呢?没有,还有一个大问题。
临床试验结果得到的是A组和B组患者的疗效差异的结论,但是我们需要的是A药和B药的疗效差异的结论。两者有区别吗?当然,大大的不同。A组和B组患者仅仅是服用A药和B药的患者的两组样本,而不等同于服用A药和B药的所有同类患者的总体。
通过随机对照双盲这样的严格的控制试验条件的方法,得到的结论也许是可靠的,但是仅从两组样本得到的结论是否可以推之于总体?这个结论有没有偶然性?换句话说,我们换一批样本或者改变每一组样本的数量是否还能够得到同样的结论?抑或结论会发生翻转?
那么如何避免或者降低结果的偶然性,从而真实的反映总体的真正效应呢?办法就是增大样本量。
样本量越大,结果可重复性越高,就越能反映总体的真实效应,这个判断有科学依据吗?这时候,伯努利的大数定律就出场了。大数定律告诉我们,在不确定性事件大量重复出现中,往往呈现几乎必然的规律。
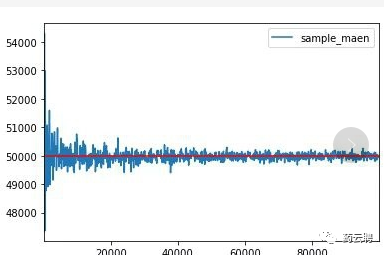
换句话说,样本量太小就无法揭示迷雾中的真相,样本量越大,试验结果越接近真实值。但是,同时又产生一个问题,是不是样本量越大越好呢?一定数量的样本量是保证科学性的前提,但是显而易见,样本量太大则费时费力费钱,而且如果让不必要的受试者置于临床试验的风险之中,这是不符合伦理的,违背了“伤害最少”的原则。
那么,样本量到底多大才算可以保证实现结果可重复性的最小样本量呢?试验的结果不可能有百分百的可重复性。我们只能在试验之前考虑清楚,我们需要在什么标准下,以多大概率实现可重复性。
如果要证明A药的疗效优于B药,我们首先针对每一个研究案例进行明确的界定:优效的标准是什么?比如,治疗糖尿病的A药和B药,到底两者在降低血糖的效果上差距达到多少才算是优或者劣?这个疗效指标值的差距需要明确的量化,通常由临床专家来界定。
再则,重复试验的结果,仍然有一定犯错的可能。比如,本来A药和B药的疗效没有差异,而我们的试验结果却有差异,或者反之。因此,在每个具体的临床试验设计中,需要预先决定我们可以容忍的结果犯错的概率,这需要统计学家的参与。
在以上参数设定的基础上,就可以通过公式来计算样本量了,这个样本量就是在设定的参数前提条件下,临床试验中需要的最小样本量。
到此为止,临床试验设计的四大原则——对照、双盲、随机以及重复,都已一一呈现。这四大基本原则,构成了随机对照临床试验(Randomized Controlled Trial, RCT)的基本要义,是目前药物临床试验设计的“金标准”。
从詹姆斯·林德开始,人类用了200多年的时间,直到20世纪中叶,才建立起这样一套“金标准”,可以说是穷尽了一切可能的努力,最大限度地降低了干扰因素对试验结果评价的影响,增加了试验结果的可重复性,抵达了真理的彼岸。
然而,这里所追求的真理是经过对照、双盲、随机这样严格控制条件下得到的真理,是“理想世界”的真理。
而“真实世界”可能跟“理想世界”不太一样,在真实世界里,患者的情况是非常复杂而各异的,特殊人群同样可能是服药对象,患者也可能随时换药,抑或同时患有多种疾病,另外对治疗的依从性也不一定好。
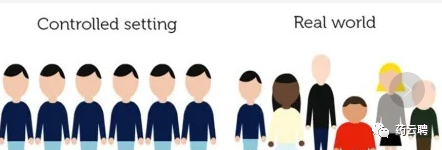
更重要的是,理想世界和真实世界追求的目的其实有本质不同。前者是为了对药物疗效做出评价,为通过审批提供依据,无论从企业的成本限制还是患者的迫切需求来讲,都不允许试验做太长时间。因此,在有限的时间里,只能观察一些短期的、直接的疗效评价指标,而对于生存期的评价就比较难了。而生存期却正是患者所关注的。
真实世界研究(Real world study, RWS)应运而生。RWS有很多好处,但是也存在很多问题,由于数据来源于真实世界,数据的质量可能不高,形式也不标准……
为什么在讨论临床试验方法学发展的最后,要说到RWS呢?概括来说,RCT需要回答的问题是“药物是否有效和安全,并得到审批上市”;RWS所要回答的问题是“药物上市后,在临床实践中能否作为有效医疗手段”。因此,RCT和RWS两者不是相互取代,而是相互补充的关系,各有价值,缺一不可。
回顾关于临床试验方法学发展的一路历程,从“神农尝百草”时代到RCT的产生、发展及成熟,是从“真实世界”进入“理想世界”的过程;而从RCT到RWS,人类又从“理想世界”回到了“真实世界”。
正所谓,看山是山,看山不是山,看山还是山。
百度浏览 来源 : 网络

版权声明:本网站所有注明来源“医微客”的文字、图片和音视频资料,版权均属于医微客所有,非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源:”医微客”。本网所有转载文章系出于传递更多信息之目的,且明确注明来源和作者,转载仅作观点分享,版权归原作者所有。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。 本站拥有对此声明的最终解释权。










































 关注公众号
关注公众号 安卓客户端
安卓客户端










发表评论
注册或登后即可发表评论
登录注册
全部评论(0)