
人类的基因组常被比作是一本书写生命的“天书”,只有A、T、C、G四种“字母”——代表构成DNA的四种碱基,但字数多达60亿个,分布在23对染色体中,无穷的组合蕴含着人类进化、生老病死的无数奥秘。21世纪之初,人类基因组序列的第一版草图问世,尽管并不完整,却已经在生物医学领域产生了深远的影响,为临床研究、药物开发和医疗实践的发展提供指引。
▲相关阅读:基因组测序的17座丰碑 |《自然》(图片来源:123RF)
时隔二十一年,人类基因组测序领域迎来了新的里程碑:一份更完整的、无间隙的人类参考基因组。本周,《科学》杂志同时上线的6篇论文中,一个名为“端粒到端粒”联盟(T2T)的国际科研团队宣布完成了最新的人类参考基因组(被命名为T2T-CHM13),包括所有22条常染色体和X染色体的无缝组装。其序列包含30.55亿对碱基,不仅在过去的基础上增加了近 2亿碱基的遗传信息——相当于一条人类染色体包含的信息,还纠正了过往基因组序列上的许多错误,并解锁了人类基因组中结构最为复杂的一些区域。
▲《科学》杂志以封面报道和专题的形式介绍了人类基因组测序新成果(图片来源:《科学》杂志官网)
填补最后8%的空白
由于当时的测序技术所限,第一版人类基因组测序草图中留有许多空白。2013年完成的新版本并经过2019年的更新后,人类基因组测序结果中仍有数百万个碱基由字母“N”表示,代表着该位置的实际碱基未知。更重要的是,占人类基因组大约8%的生物学重要区域处于未探明的状态。为了填补最后的空白,来自几十个研究机构的近100名科学家组成了大型团队“T2T联盟”,也就是对每条染色体从一端的端粒到另一端的端粒进行测序。随着此次研究成果的集中发表,用团队领导人之一、华盛顿大学Evan Eichler教授的话说,我们在生命天书中“读到了以前从未读过的章节”。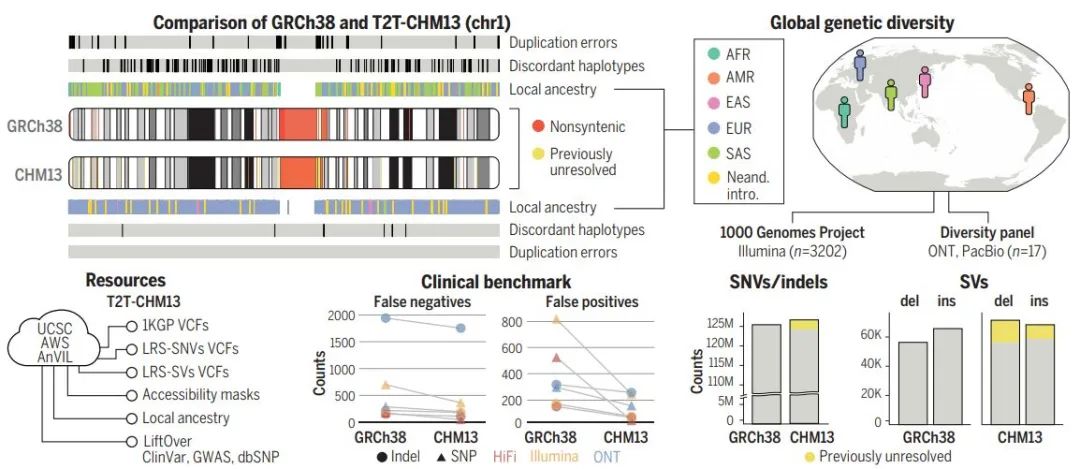
▲相比先前的人类参考基因组(GRCh38),此次的新版本T2T-CHM13填补了所有原先的空白,在过去未解决的基因组区域内,每个样本中发现了数十万个变异,为理解进化和生物医学新发现提供机会(图片来源:参考资料[2])
读取基因组时,科学家首先将所有DNA切成数百到数千个字母长的片段,由测序机器读取每个片段中的字母,然后科学家们试图以正确的顺序组装片段,就像玩一个超级复杂的拼图。这个过程中的一大挑战是,基因组中的某些区域由大段重复字母组成,就像拼图中有些板块由看起来一样的碎片组成,而这些区域往往具有重要的生物学特征,某些情况下还与人类疾病有关。另一个难点是,绝大多数细胞内包含两套基因组,分别来自父亲和母亲。当研究人员试图组装DNA片段时,两套基因组的序列混合在一起,就掩盖了两者本身具有的差异。
▲这项研究汇集了近百名科学家挑战人类基因组的完整测序研究团队找到了一种只含单个基因组的细胞系来消除上述等位基因多样性的问题。这种特殊的细胞系来自所谓的葡萄胎,是一种异常胚胎,受精后仅保留一个亲本的基因组副本。攻克难关的关键进展还离不开测序技术的重大飞跃。基于具有革命性突破的长读长测序技术,研究者可以解码更长的序列,甚至一次准确读取多达百万级的碱基对也不成问题。此次解锁的新序列大约90%来自染色体的着丝粒。在形成精子或卵子的减数分裂过程中,着丝粒是成对染色体分离时附着的地方。这个区域结构独特,包含长段重复序列,而且DNA和蛋白质似乎在这一区域缠绕得格外紧凑。
在T2T提供完整序列后,人类第一次有机会对着丝粒及其周围序列的作用一探究竟。根据他们的分析,着丝粒以及附近区域有各种序列堆叠现象,通常是一段新序列覆盖在旧序列上。这一过程可以保证着丝粒与关键的动粒结构紧紧结合。动粒是着丝粒两侧的特化结构,参与染色体的移动过程。
▲着丝粒是一个包含高度重复 DNA 序列的区域,比较这些序列揭示了突变在数百万年中积累的位置,反映了每个重复序列的相对年龄(图片来源:参考资料[4];Credit:Nicolas Altemose, UC Berkeley)
旧序列会存在一些随机突变和缺失,说明这一段区域已经被弃用;新序列中突变和甲基化都更少,说明正在被使用。而着丝粒中含有大量重复长度的DNA序列,大约为171个碱基,这些重复单元会共同形成更大的重复结构并串联多次,构成了着丝粒中的重复序列区域。着丝粒的重复序列在不同人之间同样会存在差异。其中一篇论文比较了全世界1600人的着丝粒序列后发现,非洲大陆以外的人,着丝粒(尤其是X染色体上的着丝粒)倾向于分成两大簇,还有一些有意思的突变会出现在有非洲人血统的人身上。未来,科学家或许能通过解析着丝粒序列来追溯人类的谱系,对人类的演化史探索有重要意义。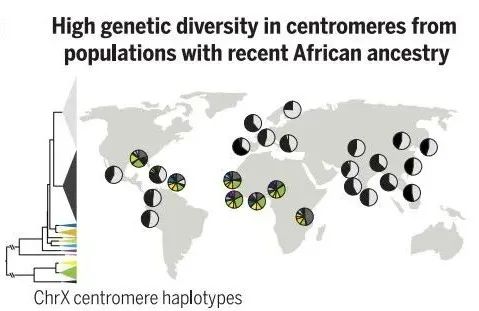
▲新研究揭示了人类着丝粒基因组序列的演化机制(图片来源:参考资料[4])在此次发表的一系列成果中,研究人员着重分析了基因组中的重复片段在人类演化、遗传多样性的形成以及疾病中的重要作用。
重复片段(segmental duplication)是基因组中反复出现的、序列相似性超过90%以上的大段序列。无论是物种内还是物种之间的演化过程中,大多数的遗传变异都出现在重复片段区域,这里是产生新基因和新基因功能发生适应性变化的关键。但由于结构的复杂性,这里也是人类基因组中最后得到完整测序的区域。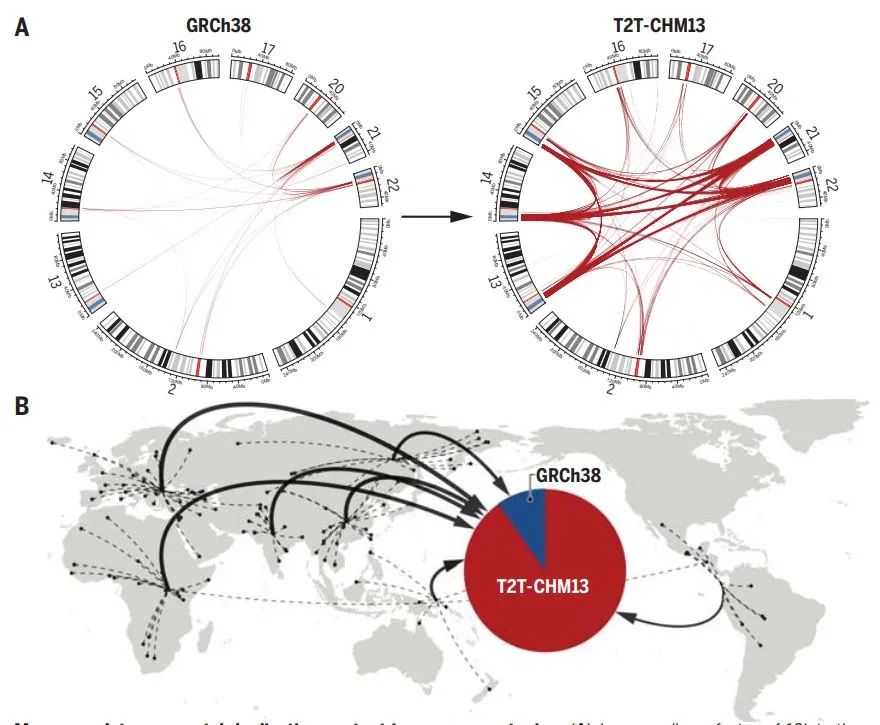
▲更完整的人类基因组测序结果加深我们对重复片段的理解(图片来源:参考资料[3])
现在,基于最新的完整人类基因组测序结果,科学家终于能够以更综合的视角审视人类的重复片段。在这类区域,科学家找到了182个全新的蛋白质编码基因,并且帮助我们理解一系列重要的演化与医学难题。例如,比较人类与其他灵长类动物的测序结果,研究发现了与人类前额叶皮层扩张相关的基因TBC1D3,这将有助于重现古人类演化的历史。而在不同人类个体间,在重复片段区域编码脂蛋白的LPA基因,其数量与心血管疾病风险高度相关……基于这项研究,我们能够全面理解重复片段的组织、表达与调控,并提升基因注释与基因分型。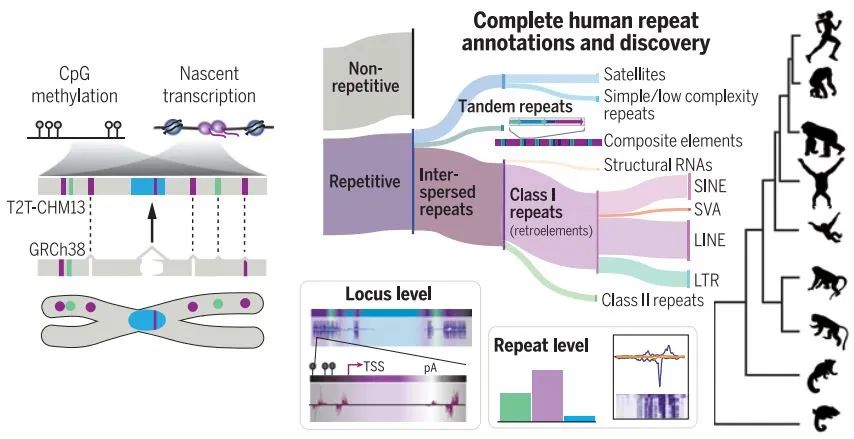
▲详细描绘了人类基因组中重复序列的转录和甲基化状态,为功能研究奠定基础(图片来源:参考资料[6])
在另一项研究中,康涅狄格大学Rachel O'Neill教授领导的团队揭示了重复序列的转录与表观遗传状态。重复序列包含移动遗传元件,它们可以移动至基因组的其他区域。研究指出,一些多次重复的片段所包含的基因,能在很大程度上解释人类的遗传多样性。除了从基因组的角度揭示特定重复序列对人类的影响,这项研究还从局部(例如着丝粒中)分析了重复序列的转录图景、描绘了甲基化的情形。这些结果将帮助我们理解转录在基因组稳定性以及染色体分离机制中的作用。O'Neill教授表示,接下来他们计划对更多不同人群进行基因组测序,从而更全面地理解人类多样性、疾病机制,以及我们与其他灵长类近亲的关系。“生成真正完整的人类基因组序列代表了一项令人难以置信的科学成就,为我们的DNA蓝图提供了第一份全面视图,”美国国家基因组研究所主任Eric Green博士评论说。《科学》杂志的专题则这样总结:最新的人类参考基因组代表着“重要的一步,表明可以组装代表所有人类的模型,这将更好地支持个体化医疗、人口基因组分析和基因组编辑。”
[1] Sergey Nurk et al., (2022) The complete sequence of a human genome. Science. Doi: 10.1126/science.abj6987[2] Sergey Aganezov et al., (2022) A complete reference genome improves analysis of human genetic variation. Science DOI: 10.1126/science.abl3533[4] Complete genomic and epigenetic maps of human centromeres. Science(2022), DOI: 0.1126/science.abl4178[5] A. Gershman et al., Epigenetic patterns in a complete human genome. Science 376, eabj5089 (2022). DOI: 10.1126/science.abj5089[6] S. J. Hoyt et al., (2022) From telomere to telomere: The transcriptional and epigenetic state of human repeat elements Science DOI: 10.1126/science.abk3112
百度浏览
来源 : 学术经纬
版权声明:本网站所有注明来源“医微客”的文字、图片和音视频资料,版权均属于医微客所有,非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源:”医微客”。本网所有转载文章系出于传递更多信息之目的,且明确注明来源和作者,转载仅作观点分享,版权归原作者所有。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。 本站拥有对此声明的最终解释权。











































 关注公众号
关注公众号 安卓客户端
安卓客户端










发表评论
注册或登后即可发表评论
登录注册
全部评论(0)